Variable selection methods are techniques used to determine the most relevant and impactful features or variables in a dataset. These methods help to improve the accuracy and efficiency of machine learning models by focusing only on the most important variables, thereby reducing noise and enhancing predictive performance.
Variable selection is important in data mining because it helps to improve the quality and efficiency of predictive models, reduces complexity, and enhances the interpretability of results.
Popular variable selection methods
Some popular variable selection methods in data mining include:
Best Subset Selection: It evaluates all possible combinations of predictors (features) to find the best subset of variables that minimizes a chosen criterion, such as the Akaike Information Criterion (AIC) or the Bayesian Information Criterion (BIC).
Forward Selection: This method starts with an empty set of variables and adds one variable at a time based on their individual contribution to the model’s performance.
Backward Elimination: In contrast to forward selection, backward elimination starts with all variables included in the model and removes them one at a time based on their individual contribution to the model’s performance.
Lasso Regression: Lasso (Least Absolute Shrinkage and Selection Operator) is a regularization technique that penalizes the absolute size of coefficients, effectively setting some coefficients to zero and performing feature selection.
Random Forest Feature Importance: Random Forest algorithm can be used to measure the importance of each feature based on how much the tree nodes that use that feature reduce impurity on average.
Application: Spam detector
Jennifer Lee is a data scientist working for a telecommunications company. The company has been experiencing a surge in customer complaints about receiving spam and phishing emails that attempt to steal personal information. Jennifer is tasked with developing a machine learning model to detect and filter out these useless or malicious emails. Her objective is to implement spam filters that analyze the email content for suspicious URLs, phishing keywords, and unusual sender behavior to proactively protect customers from falling victim to phishing attacks.
The objective is to detect spam based on the number of recipients, the number of hyperlinks, and the number of characters for each email.
# Reading the "Spam.csv" file from the URL and storing it in the 'Spam' dataframe.Spam <-read.csv("https://www.educateusgpt.org/examples/Spam.csv", header =TRUE)# Providing a summary of the 'Spam' dataframe, including statistical summaries.summary(Spam)
Record Spam Recipients Hyperlinks
Min. : 1.0 Min. :0.000 Min. :12.00 Min. : 0.000
1st Qu.:125.8 1st Qu.:0.000 1st Qu.:12.00 1st Qu.: 3.000
Median :250.5 Median :1.000 Median :13.00 Median : 6.000
Mean :250.5 Mean :0.516 Mean :14.42 Mean : 6.226
3rd Qu.:375.2 3rd Qu.:1.000 3rd Qu.:15.00 3rd Qu.: 9.000
Max. :500.0 Max. :1.000 Max. :52.00 Max. :12.000
Characters
Min. : 18.0
1st Qu.: 38.0
Median : 58.0
Mean : 58.6
3rd Qu.: 79.0
Max. :103.0
# Remove the useless 'Record' columnSpam <- Spam[,-1]
Fit the logistic regression model
Develop the logistic regression model for the Spam dataset.
# Splitting dataset to be training and testing sets.# sample_index <- sample(nrow(Spam), nrow(Spam)*0.80)# train <- Spam[sample_index,]# test <- Spam[-sample_index,]# or use a more straightforward splittingtrain <- Spam[1:400,]test <- Spam[401:500,]# Train a logistic regression model with all variablesLogit_mod <-glm(Spam ~ Recipients + Hyperlinks + Characters,data = train, family = binomial)# Print the summary of the modelsummary(Logit_mod)
Call:
glm(formula = Spam ~ Recipients + Hyperlinks + Characters, family = binomial,
data = train)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -4.807162 0.812737 -5.915 3.32e-09 ***
Recipients 0.160926 0.042556 3.782 0.000156 ***
Hyperlinks 0.523397 0.049921 10.484 < 2e-16 ***
Characters -0.010583 0.005542 -1.910 0.056181 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 553.71 on 399 degrees of freedom
Residual deviance: 353.62 on 396 degrees of freedom
AIC: 361.62
Number of Fisher Scoring iterations: 5
Best subset selection
It evaluates all possible combinations of predictors (features) to find the best subset of variables that minimizes a chosen criterion, such as the Akaike Information Criterion (AIC) or the Bayesian Information Criterion (BIC).
If you cannot write your own codes, try to ask EducateUsGPT assistant to help you out.
Ask Educate Us GPT
Show me the sample codes in R to apply best subset selection method on the model object 'Logit_mod'?
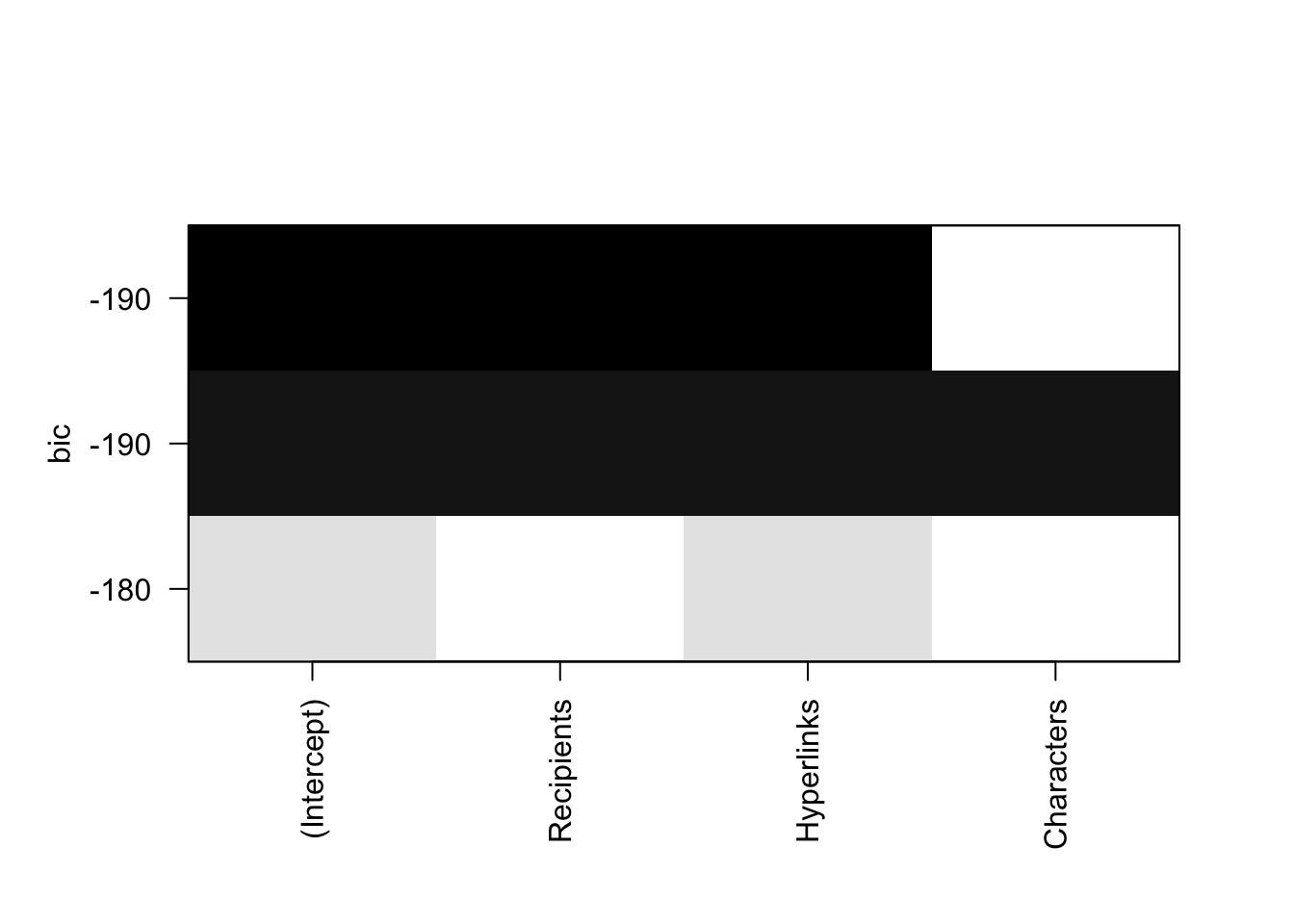
# Load the leaps package for regsubsets functionlibrary(leaps)# Generate all possible models and select the best subsetbest_subset_model <-regsubsets(Spam ~ ., data = train, nbest=1, nvmax =3)# Extract the best subset modelbest_model <-summary(best_subset_model)best_model
To perform the Forward/Backward/Stepwise Regression in R, we need to define the starting models:
# nullmodel is the model with no varaible in it,nullmodel <-lm(Spam ~1, data=train)# while fullmodel is the model with every variable in it.fullmodel <- Logit_mod
Start: AIC=361.62: This indicates the starting Akaike Information Criterion (AIC) value before any variables are removed or added.
- Recipients, - Characters, - Hyperlinks: These lines represent the potential improvement in AIC if each variable is removed from the model individually. However, removing any one of them would lead to an increase in AIC or RSS, indicating a worse model fit. Therefore, the best model should be the starting model with all three predictors included.
Start: AIC=-553.33, Spam ~ 1. It shows adding the ‘+ Hyperlinks’ decreases the AIC the most. So the algorithm decides to add the ‘Hyperlinks’.
Step: AIC=-739.99 shows the AIC for the model Spam ~ Hyperlinks. Based on this model, adding the ‘+ Recipients’ decreases the AIC again to be -762.15 So it should add ‘Recipients’ to the model.
Likewise, in the third step, the final AIC value after adding ‘Characters’ to the model decreases to -763.73, which indicates that this is the best model with the lowest AIC value with all three predictors: ‘Hyperlinks’, ‘Characters’, and ‘Recipients’.
Does the Forward selection give you the same selected model?
Stepwise Selection (Output Omitted)
Ask Educate Us GPT
Show me the sample codes in R to apply stepwise selection method on the model object 'Logit_mod'?
# Applying stepwise selectionstepwise_model <-step(Logit_mod, direction ="both")