library(readr)
Morgage <- read_csv("examples/Morgage.csv", show_col_types = FALSE)Logistic regression and classifications
Logistic regression and classifications
Please read the lecture to gain the understanding of logistic regression.
Application 1: Mortgage loan
The Great Recession has forced financial institutions to be extra stringent in granting mortgage loans. Thirty recent mortgage applications are obtained to analyze the mortgage approval rate.
The response variable \(y\) equals 1 if the mortgage loan is approved, 0 otherwise. It is believed that approval depends on the percentage of the down payment (\(x_1\)) and the percentage of the income-to-loan ratio (\(x_2\)).
Download and import the Morgage.csv dataset
| y | x1 | x2 |
|---|---|---|
| 1 | 16.35 | 49.94 |
| 1 | 34.43 | 56.16 |
| 1 | 39.19 | 36.89 |
| 1 | 23.58 | 56.88 |
| 0 | 29.92 | 27.05 |
| 1 | 25.26 | 44.38 |
| 1 | 36.51 | 48.98 |
| 1 | 11.70 | 55.55 |
| 0 | 32.21 | 31.28 |
| 1 | 28.74 | 35.63 |
| 1 | 18.28 | 39.50 |
| 0 | 10.12 | 31.39 |
| 0 | 10.39 | 29.47 |
| 0 | 21.46 | 29.34 |
| 1 | 33.56 | 40.37 |
| 1 | 37.91 | 22.92 |
| 1 | 31.81 | 47.56 |
| 0 | 25.88 | 44.58 |
| 1 | 38.40 | 47.85 |
| 0 | 26.62 | 25.50 |
| 0 | 14.36 | 21.87 |
| 1 | 22.22 | 20.79 |
| 1 | 32.10 | 51.56 |
| 0 | 11.75 | 32.96 |
| 1 | 10.32 | 48.59 |
| 0 | 11.43 | 34.78 |
| 0 | 12.58 | 33.27 |
| 0 | 27.53 | 25.63 |
| 1 | 36.71 | 37.05 |
| 0 | 17.85 | 26.86 |
Fit the linear probability model
The linear probability model is a straightforward approach in statistics and econometrics that models the relationship between a binary outcome (like Yes/No) and one or more predictor variables using linear regression techniques.
Try to ask EducateUsGPT assistant to figure out the codes that can help you to develop the linear probability model for the mortgage dataset.
Ask Educate Us GPT
How to fit a linear probability model in R for the dataset that has y as response, x1 and x2 as predictors?
After calling the help from the EducateUsGPT assistant, you can double check if your codes could fit the similar linear probability model as follows:
# Assuming your dataset is named 'data'
LPM_mod <- lm(y ~ x1 + x2, data = Morgage)
# Print the summary of the model
summary(LPM_mod)Fit the logistic regression model
Try to ask EducateUsGPT assistant to figure out the codes that can help you to develop the logistic regression model for the mortgage dataset.
Ask Educate Us GPT
What question you should ask?
After calling the help from the EducateUsGPT assistant, you can double check if your codes could fit the logistic regression model as follows:
# Dataset is named as 'Morgage'
Logit_mod <- glm(y ~ x1 + x2, data = Morgage, family = binomial)
# Print the summary of the model
summary(Logit_mod)Compare these two models
Compare and interpret the estimation of the two models you developed above.
| Dependent variable: | ||
| y | ||
| OLS | logistic | |
| (1) | (2) | |
| x1 | 0.019** | 0.135** |
| (0.007) | (0.064) | |
| x2 | 0.026*** | 0.178*** |
| (0.006) | (0.065) | |
| Constant | -0.868*** | -9.367*** |
| (0.281) | (3.196) | |
| Observations | 30 | 30 |
| R2 | 0.506 | |
| Adjusted R2 | 0.469 | |
| Log Likelihood | -10.917 | |
| Akaike Inf. Crit. | 27.835 | |
| Residual Std. Error | 0.367 (df = 27) | |
| F Statistic | 13.819*** (df = 2; 27) | |
| Note: | p<0.1; p<0.05; p<0.01 | |
Predict a loan application
Predict the loan approval probability for an applicant with a 20% down payment and a 30% income-to-loan ratio using the two models respectively.
# Predict using LPM
predict(LPM_mod,
newdata = data.frame(x1 = 20, x2 = 30),
type='response') 1
0.283569 # Predict using logistic regression model
predict(Logit_mod,
newdata = data.frame(x1 = 20, x2 = 30),
type='response') 1
0.2104205 What if the down payment was 5%, income-to-loan ratio was 20%?
# Predict using LPM
predict(LPM_mod,
newdata = data.frame(x1 = 5, x2 = 20),
type='response') 1
-0.2573356 # Predict using logistic regression model
predict(Logit_mod,
newdata = data.frame(x1 = 5, x2 = 20),
type='response') 1
0.005892842 Why the linear probability model is not appropriate for the prediction of a binary outcome?
Hint: what you’ve found from the prediction above.
Ask Educate Us GPT
What is the drawback of the linear probability model?
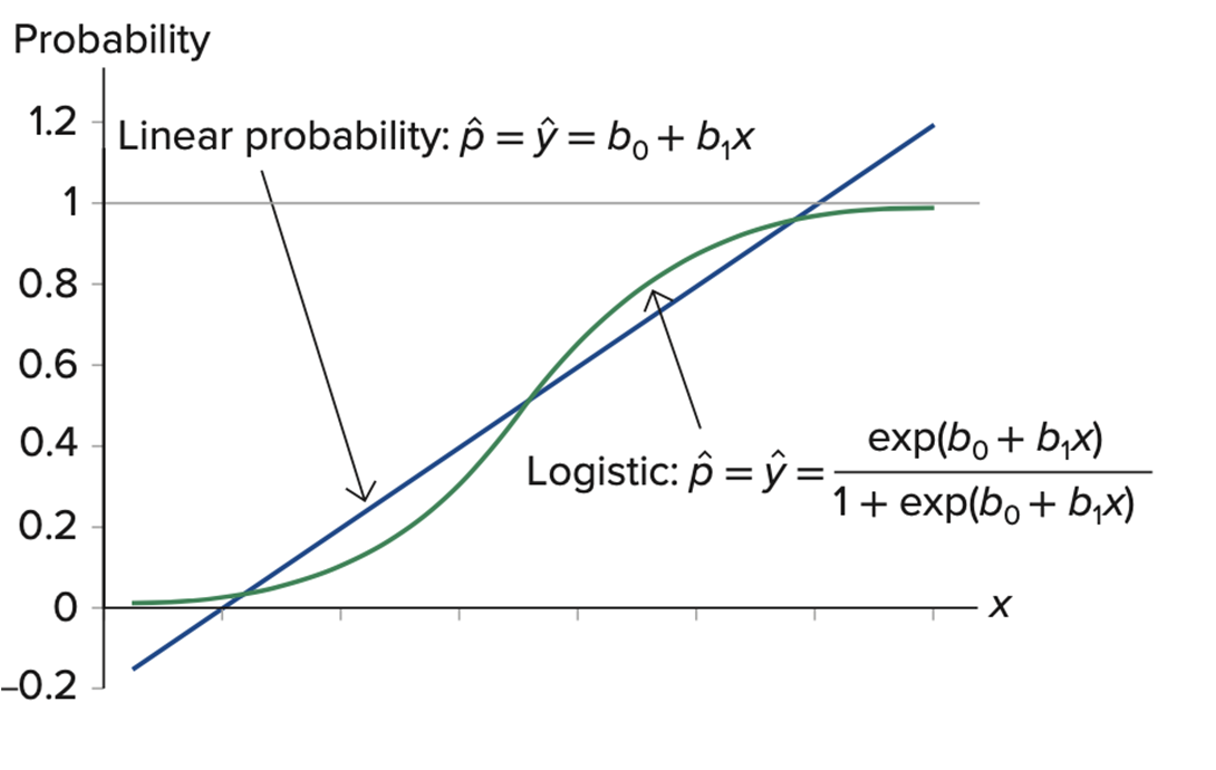
As shown in the above figure, the linear probability model can lead to predicted probabilities that are outside the range of 0 to 1 at the extreme ends of the predictor variable values. The predicted probabilities that are negative or greater than 100% are not meaningful and interpretable. So it is more appropriate to use a logistic regression model for the classification of the problems with a binary outcome such that the predicted probability is always within the rage of 0 to 1.
Predict all applications in training and testing sets
For the logistic regression models, you can predict the log odds ratio, the probability being 1, or you can have binary predicted outcome of 0 or 1 given a cut-off probability.
- In logistic regression, the \(\hat{\eta}\) are called log odds ratio, which is \(\log(P(y_i=1)/(1-P(y_i=1)))\). The fitted model \(\hat{\eta} = b_0 +b_1 x_1 + b_2 x_2 + ...\) provides the estimated log odds ratio before the inverse of link (such as the logit function in logistic regression). In R, the
predict()function is utilized to obtain a vector containing all in-sample \(\hat{\eta}\) values for each training observation.
hist(predict(Logit_mod))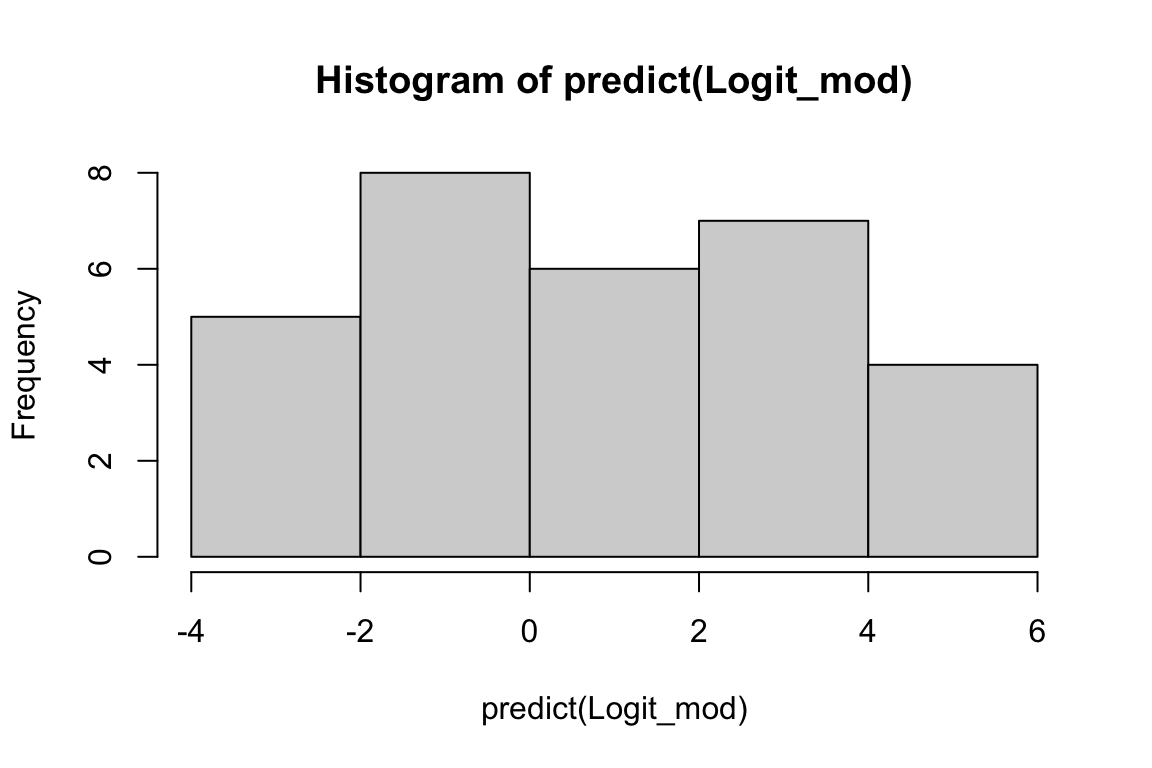
- To calculate the predicted probability \(P(y_i=1)\), you apply the inverse of the link function (in this case, the logit function) to \(\hat{\eta}\). This is expressed by the equation \(P(y_i=1) = 1 / (1 + \exp(-\hat{\eta}_i))\). In R, you can obtain the predicted probability for each training observation using either the
fitted()function orpredict(, type="response").
pred_resp <- predict(Logit_mod, type="response")
hist(pred_resp)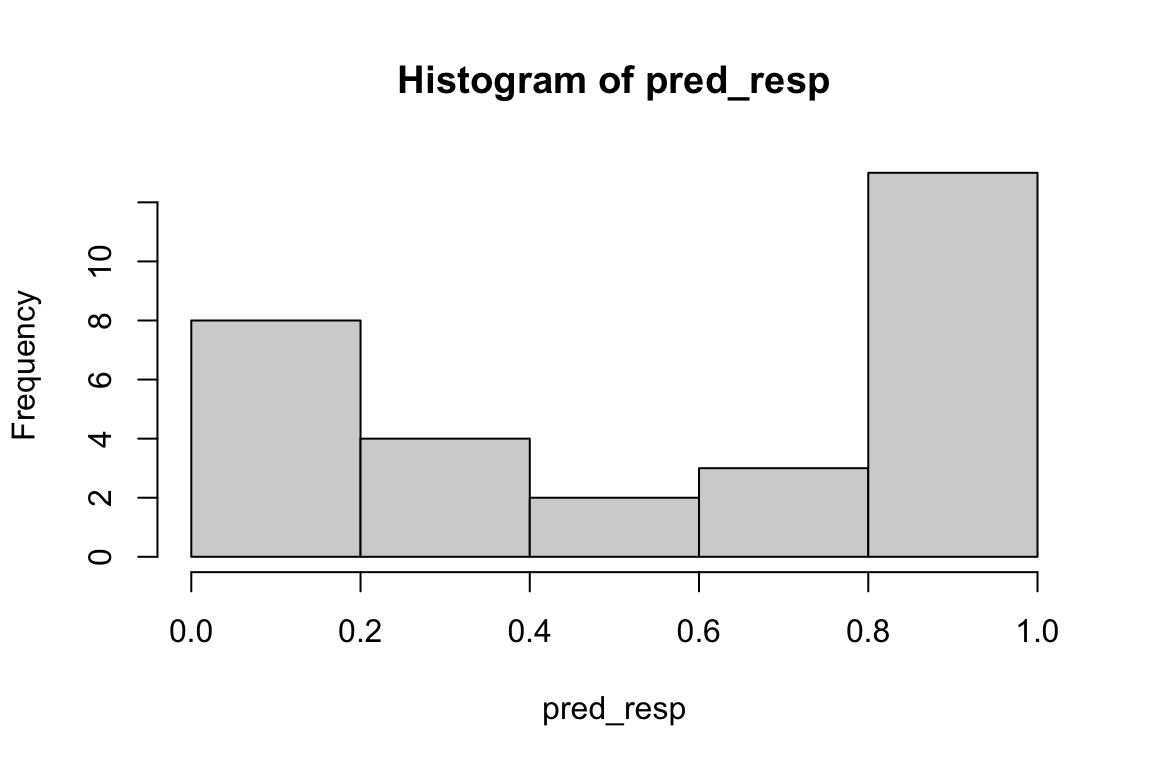
- Finally, consider the necessity of a binary classification decision rule. An intuitive rule is to assign the outcome a value of 1 if the estimated probability (\(P(y=1)\)) exceeds 0.5. This threshold probability of 0.5 is commonly referred to as the cut-off probability. However, it’s crucial to note that you have the flexibility to adjust this cut-off probability according to various factors such as the misclassification rate or the implications of the decision. For instance, one may weigh the cost function, which assesses the balance between the risk of approving a loan for someone unable to repay (predicting 0 when the truth is 1) and the risk of denying a loan to someone who is qualified (predicting 1 when the truth is 0).
These tables (confusion matrix) below illustrate the impact of choosing different cut-off probabilities. Choosing a large cut-off probability will result in few cases being predicted as 1, and choosing a small cut-off probability will result in many cases being predicted as 1.
# This line of code generates a contingency table comparing the actual values of the response variable 'y' in the Logit_mod dataset
# with the predicted values obtained from the logistic regression model 'pred_resp'.
# The predicted values are dichotomized using a threshold of 0.5, where any value greater than 0.5 is classified as 1 and any value less than or equal to 0.5 is classified as 0.
# The resulting table displays the counts of observations where the actual value and the predicted value fall into each category.
table(Logit_mod$y, (pred_resp > 0.5)*1, dnn=c("Truth","Predicted")) Predicted
Truth 0 1
0 11 2
1 2 15# This line of code is similar to the previous one, but it uses a different threshold value of 0.2 to dichotomize the predicted values.
# Consequently, the resulting table provides counts of observations based on a lower threshold for predicting the positive class (1).
table(Logit_mod$y, (pred_resp > 0.2)*1, dnn=c("Truth","Predicted")) Predicted
Truth 0 1
0 7 6
1 1 16# This line of code again generates a contingency table, but this time using an extremely low threshold value of 0.0001 to dichotomize the predicted values.
# As a result, almost all predicted values are likely to be classified as 1.
# This table helps to understand the impact of setting an extremely low threshold on the classification of observations.
table(Logit_mod$y, (pred_resp > 0.0001)*1, dnn=c("Truth","Predicted")) Predicted
Truth 1
0 13
1 17Ask Educate Us GPT
what is the limitation of evaluating confusion matrix of the logistic regression model with only one specific cut-off-probability?
One limitation is that the choice of the cut-off probability can significantly impact the model evaluation metrics such as accuracy, precision, recall, and F1 score. Different cut-off probabilities can lead to different trade-offs between true positive rate and false positive rate, making it challenging to accurately assess the model’s overall performance.
Practitioners often use Receiver operating characteristic (ROC) curves or precision-recall curves evaluate the model’s performance across various cut-off probabilities and gain a more comprehensive understanding of its predictive power.
Fitting performance
Why should we evaluate fitting performance of a logistic regression model?
Model Validation: validatting model’s effectiveness in capturing the underlying relationships between the predictors and the target variable.
Model Comparison: we may need to try a few different models and select the one that best balances model complexity and fitting performance. Metrics like pseudo-\(R^2\), AIC, and BIC help in comparing models with different combination of predictors to find the effective model.
There are a few key metrics one can use to evaluate the fitting performance of a logistic regression model. For example,
- AIC and BIC,
- Residual deviance (equivalent to SSE in linear regression model),
- mean residual deviance,
- pseudo-\(R^2\),
- Likelihood Ratio Test
AIC and BIC
Why is the information criteria useful for evaluating logistic regression model’s performance?
AIC and BIC try to find the best model that minimizes the information loss in representing the data. They achieve this by penalizing models for their complexity, effectively discouraging the inclusion of unnecessary variables that do not significantly improve the model’s performance.
Akaike Information Criterion (AIC): \[\text{AIC} = -2 * \text{log-likelihood} + 2 * p\]
- where \(\text{log-likelihood}\) is the maximized value of the likelihood function of the model.
- \(p\) is the number of parameters in the model.
Bayesian Information Criterion (BIC): \[BIC = -2 * \text{log-likelihood} + \log(n) * p\]
- \(n\) is the sample size.
- \(p\) is the number of parameters in the model.
Lower values of AIC and BIC indicate a better fit, taking into account the trade-off between model complexity and fit. One can use them to compare different models and choose the one that provides a good balance between goodness of fit and complexity, helping to avoid overfitting and select the most appropriate model for the given data.
Ask Educate Us GPT
How to calculate the AIC and BIC for a logistic regression model in R?
# AIC() and BIC() function can work with linear models and logistic models.
cat("AIC of Linear probability model:", AIC(LPM_mod))AIC of Linear probability model: 29.86295cat("BIC of Linear probability model:", BIC(LPM_mod))BIC of Linear probability model: 35.46774cat("AIC of logistic regression model:", AIC(Logit_mod))AIC of logistic regression model: 27.8346cat("BIC of logistic regression model:", BIC(Logit_mod))BIC of logistic regression model: 32.03819Residual deviance and mean residual deviance
Why the residual deviance can be used for evaluating a logistic regression model
It assesses how well a logistic regression model fits the data. It is the difference between the deviance of the model being evaluated and the deviance of a saturated model (a model with a perfect fit). In simpler terms, residual deviance tells us how much information about the response variable is not explained by the model.
\[D = 2\log\left(\frac{L_{sat}(\hat{\beta})}{L_{model}(\hat{\beta})}\right) = 2(\ell_{sat}(\hat{\beta})-\ell_{model}(\hat{\beta})),\] where
- \(\ell_{sat}(\hat{\beta})\) is the log-likelihood of the full (saturated) model that measures how well the model predicts the observed data.
- \(\ell_{model}(\hat{\beta})\) is the log-likelihood of the fitted model.
A lower residual deviance indicates a better fit of the model to the data, while a higher residual deviance suggests that the model does not fit the data well.
# training set residual deviance
Logit_mod$deviance[1] 21.8346# training set mean residual deviance using df
Logit_mod$deviance/Logit_mod$df.residual [1] 0.8086888A comprehensive explanation for the saturated models and deviance is here
Pseudo-\(R^2\)
Ordinary least squares (OLS) \(R^2\) is designed as a goodness-of-fit measure for the regression models with the continuous dependent variable. It indicates the overall explanatory power of a model.
\[ R^2 = 1 - \frac{\sum_{i}(y_i - \hat{y}_i)^2}{\sum_{i}(y_i - \bar{y})^2} = 1 - \frac{SSR}{SST} \]
- where \(y_i\) represents the actual values of the response variable,
- \(\hat{y}_i\) represents the predicted values,
- \(\bar{y}\) represents the mean of the response variable,
- \(SSR\) is the sum of squared residuals,
- \(SST\) is the total sum of squares.
However, for generalized linear models where the response variable is binary or ordinal, an equivalent and well-performed statistic to R-squared has long been sought. Many studies attempted to develop an analogous notion of \(R^2\) for categorical data analysis, including the Surrogate \(R^2_{Surr}\) by Liu et al. (2023), McFadden’s \(R^2_{McF}\) (McFadden, 1973) and McKelvey and Zavoina’s \(R^2_{MZ}\) (1975).
For logistic regression models,
Surrogate \(R^2_S\) is: \[ R^2_{S}= \text{the OLS } R^2 \text{ based on the simulated surrogate responses } S,\]
- \(S\) is the surrogate response simulated from a fitted linear model as shown below \[S = \hat{\alpha}_1 + \hat{\beta}_1 X_1 + \cdots + \hat{\beta}_p X_p + \varepsilon, \varepsilon \sim Logistic(0,1)\]
McFadden’s \(R^2_{McF}\) is: \[ R^2_{McF} = 1 - \frac{\ln(L_M)}{\ln(L_0)},\]
- \(L_M\) is log likelihood of the fitted model
- \(L_0\) is log likelihood of the model with just the intercept (the null model).
McKelvey and Zavoina’s \(R^2_{MZ}\) is: \[ R^2_{MZ}=\frac{\sum_{i=1}^n (\hat{z}_i - {\bar{z}})^2}{\sum_{i=1}^n (\hat{z}_i - {\bar{z}})^2 + n\pi^2/3},\]
- \(\hat{z}_i = x_{1i}{\beta}_1+\cdots+x_{q1,i}{\beta}_q\),
- \({\bar{z}} = \sum_{i=1}^n \hat{z}_i /n\)
# Surrogate R-squared of training set
library(SurrogateRsq)
surr_rsq(model = Logit_mod,
full_model = Logit_mod)------------------------------------------------------------------------
The surrogate R-squared of the model
------------------------------------------------------------------------
y ~ x1 + x2
------------------------------------------------------------------------
is:
[1] 0.66402# McFadden's Pseudo R-squared of training set
DescTools::PseudoR2(Logit_mod, which = "McFadden") McFadden
0.4681481 # McKelvey and Zavoina's Pseudo R-squared of training set
DescTools::PseudoR2(Logit_mod, which = "McKelveyZavoina")McKelveyZavoina
0.6481221 A explanation of commonly encountered Pseudo R-squareds is here
Application 2: Spam detector
Jennifer Lee is a data scientist working for a telecommunications company. The company has been experiencing a surge in customer complaints about receiving spam and phishing emails that attempt to steal personal information. Jennifer is tasked with developing a machine learning model to detect and filter out these useless or malicious emails. Her objective is to implement spam filters that analyze the email content for suspicious URLs, phishing keywords, and unusual sender behavior to proactively protect customers from falling victim to phishing attacks.
The objective is to detect spam based on the number of recipients, the number of hyperlinks, and the number of characters for each email.
Download and import the Spam.csv dataset
library(readr)
Spam <- read_csv("examples/Spam.csv")| Record | Spam | Recipients | Hyperlinks | Characters |
|---|---|---|---|---|
| 1 | 0 | 19 | 1 | 47 |
| 2 | 1 | 17 | 11 | 68 |
| 3 | 1 | 13 | 11 | 88 |
| 4 | 0 | 15 | 1 | 58 |
| 5 | 0 | 15 | 1 | 87 |
| 6 | 0 | 17 | 2 | 49 |
| 7 | 1 | 12 | 10 | 41 |
| 8 | 0 | 13 | 3 | 66 |
| 9 | 0 | 12 | 5 | 66 |
| 10 | 1 | 15 | 9 | 41 |
| 11 | 1 | 13 | 10 | 45 |
| 12 | 1 | 13 | 11 | 68 |
| 13 | 1 | 13 | 11 | 27 |
| 14 | 1 | 12 | 9 | 88 |
| 15 | 0 | 16 | 4 | 26 |
| 16 | 1 | 12 | 12 | 52 |
| 17 | 1 | 13 | 11 | 70 |
| 18 | 1 | 12 | 11 | 39 |
| 19 | 1 | 13 | 11 | 102 |
| 20 | 1 | 13 | 3 | 65 |
| 21 | 0 | 12 | 6 | 47 |
| 22 | 0 | 13 | 2 | 81 |
| 23 | 1 | 25 | 7 | 79 |
| 24 | 1 | 18 | 5 | 42 |
| 25 | 0 | 13 | 0 | 27 |
| 26 | 1 | 15 | 11 | 25 |
| 27 | 0 | 14 | 3 | 47 |
| 28 | 1 | 16 | 11 | 93 |
| 29 | 1 | 13 | 7 | 93 |
| 30 | 1 | 13 | 5 | 28 |
| 31 | 1 | 14 | 11 | 91 |
| 32 | 1 | 23 | 9 | 58 |
| 33 | 1 | 14 | 9 | 36 |
| 34 | 0 | 18 | 3 | 89 |
| 35 | 1 | 12 | 10 | 97 |
| 36 | 0 | 18 | 0 | 103 |
| 37 | 1 | 15 | 11 | 70 |
| 38 | 1 | 12 | 12 | 28 |
| 39 | 0 | 16 | 3 | 34 |
| 40 | 1 | 14 | 8 | 81 |
| 41 | 0 | 14 | 0 | 66 |
| 42 | 1 | 13 | 8 | 78 |
| 43 | 1 | 12 | 10 | 86 |
| 44 | 0 | 15 | 5 | 77 |
| 45 | 1 | 15 | 11 | 29 |
| 46 | 1 | 15 | 9 | 63 |
| 47 | 0 | 17 | 5 | 50 |
| 48 | 1 | 13 | 12 | 73 |
| 49 | 1 | 13 | 9 | 38 |
| 50 | 0 | 12 | 1 | 80 |
| 51 | 0 | 13 | 4 | 65 |
| 52 | 0 | 14 | 7 | 83 |
| 53 | 1 | 13 | 3 | 102 |
| 54 | 1 | 14 | 6 | 20 |
| 55 | 0 | 13 | 4 | 67 |
| 56 | 1 | 29 | 3 | 21 |
| 57 | 0 | 12 | 5 | 84 |
| 58 | 1 | 52 | 1 | 30 |
| 59 | 1 | 14 | 4 | 97 |
| 60 | 1 | 14 | 6 | 98 |
| 61 | 0 | 12 | 4 | 99 |
| 62 | 1 | 12 | 11 | 47 |
| 63 | 0 | 14 | 2 | 73 |
| 64 | 1 | 24 | 1 | 101 |
| 65 | 1 | 20 | 6 | 42 |
| 66 | 0 | 12 | 10 | 74 |
| 67 | 1 | 18 | 6 | 20 |
| 68 | 1 | 13 | 6 | 32 |
| 69 | 0 | 13 | 3 | 58 |
| 70 | 1 | 12 | 7 | 22 |
| 71 | 0 | 12 | 0 | 88 |
| 72 | 1 | 12 | 2 | 83 |
| 73 | 1 | 16 | 10 | 70 |
| 74 | 0 | 12 | 2 | 64 |
| 75 | 1 | 16 | 11 | 19 |
| 76 | 1 | 13 | 9 | 32 |
| 77 | 0 | 12 | 3 | 24 |
| 78 | 0 | 14 | 3 | 48 |
| 79 | 1 | 12 | 5 | 102 |
| 80 | 1 | 12 | 4 | 67 |
| 81 | 0 | 12 | 6 | 63 |
| 82 | 1 | 15 | 11 | 52 |
| 83 | 0 | 12 | 4 | 54 |
| 84 | 1 | 18 | 6 | 46 |
| 85 | 0 | 12 | 2 | 90 |
| 86 | 1 | 17 | 10 | 68 |
| 87 | 0 | 14 | 1 | 61 |
| 88 | 1 | 17 | 4 | 31 |
| 89 | 1 | 12 | 11 | 24 |
| 90 | 1 | 41 | 9 | 101 |
| 91 | 0 | 13 | 2 | 20 |
| 92 | 1 | 14 | 9 | 93 |
| 93 | 1 | 18 | 5 | 19 |
| 94 | 0 | 13 | 6 | 67 |
| 95 | 0 | 14 | 6 | 71 |
| 96 | 1 | 13 | 5 | 102 |
| 97 | 0 | 17 | 1 | 87 |
| 98 | 0 | 13 | 3 | 64 |
| 99 | 0 | 13 | 3 | 38 |
| 100 | 0 | 14 | 4 | 56 |
| 101 | 0 | 13 | 11 | 69 |
| 102 | 1 | 17 | 8 | 83 |
| 103 | 0 | 25 | 2 | 53 |
| 104 | 0 | 12 | 5 | 69 |
| 105 | 1 | 12 | 11 | 46 |
| 106 | 1 | 17 | 10 | 41 |
| 107 | 0 | 12 | 4 | 29 |
| 108 | 0 | 12 | 7 | 88 |
| 109 | 1 | 18 | 7 | 24 |
| 110 | 1 | 13 | 2 | 29 |
| 111 | 1 | 12 | 8 | 42 |
| 112 | 1 | 23 | 5 | 54 |
| 113 | 0 | 12 | 4 | 73 |
| 114 | 0 | 13 | 3 | 46 |
| 115 | 1 | 13 | 7 | 99 |
| 116 | 1 | 34 | 5 | 29 |
| 117 | 0 | 12 | 5 | 28 |
| 118 | 1 | 13 | 11 | 28 |
| 119 | 1 | 14 | 7 | 24 |
| 120 | 0 | 14 | 5 | 84 |
| 121 | 1 | 13 | 1 | 84 |
| 122 | 1 | 12 | 12 | 88 |
| 123 | 0 | 12 | 0 | 40 |
| 124 | 0 | 12 | 1 | 43 |
| 125 | 1 | 12 | 11 | 57 |
| 126 | 0 | 13 | 3 | 19 |
| 127 | 0 | 22 | 5 | 78 |
| 128 | 0 | 19 | 4 | 32 |
| 129 | 1 | 14 | 5 | 45 |
| 130 | 0 | 14 | 4 | 61 |
| 131 | 0 | 12 | 7 | 68 |
| 132 | 1 | 13 | 10 | 80 |
| 133 | 0 | 13 | 2 | 77 |
| 134 | 0 | 21 | 7 | 64 |
| 135 | 0 | 13 | 7 | 48 |
| 136 | 1 | 12 | 7 | 23 |
| 137 | 1 | 15 | 7 | 28 |
| 138 | 1 | 14 | 9 | 50 |
| 139 | 1 | 13 | 7 | 77 |
| 140 | 1 | 17 | 10 | 60 |
| 141 | 0 | 12 | 0 | 42 |
| 142 | 1 | 15 | 7 | 97 |
| 143 | 0 | 12 | 0 | 39 |
| 144 | 0 | 12 | 6 | 85 |
| 145 | 1 | 12 | 6 | 102 |
| 146 | 0 | 12 | 3 | 22 |
| 147 | 0 | 12 | 5 | 45 |
| 148 | 0 | 14 | 1 | 70 |
| 149 | 1 | 12 | 8 | 64 |
| 150 | 1 | 12 | 12 | 19 |
| 151 | 0 | 12 | 5 | 103 |
| 152 | 1 | 30 | 7 | 90 |
| 153 | 1 | 13 | 10 | 54 |
| 154 | 1 | 13 | 7 | 94 |
| 155 | 0 | 13 | 0 | 69 |
| 156 | 1 | 12 | 10 | 87 |
| 157 | 1 | 12 | 10 | 76 |
| 158 | 1 | 13 | 5 | 23 |
| 159 | 0 | 12 | 5 | 55 |
| 160 | 0 | 13 | 7 | 62 |
| 161 | 0 | 12 | 7 | 70 |
| 162 | 0 | 14 | 2 | 23 |
| 163 | 0 | 13 | 0 | 101 |
| 164 | 1 | 12 | 8 | 61 |
| 165 | 1 | 13 | 4 | 99 |
| 166 | 1 | 14 | 1 | 54 |
| 167 | 0 | 17 | 3 | 33 |
| 168 | 0 | 13 | 6 | 86 |
| 169 | 1 | 13 | 12 | 32 |
| 170 | 1 | 13 | 9 | 43 |
| 171 | 0 | 13 | 3 | 73 |
| 172 | 1 | 12 | 11 | 29 |
| 173 | 1 | 12 | 9 | 90 |
| 174 | 1 | 13 | 5 | 100 |
| 175 | 1 | 23 | 6 | 63 |
| 176 | 0 | 12 | 2 | 66 |
| 177 | 1 | 23 | 12 | 36 |
| 178 | 0 | 13 | 3 | 63 |
| 179 | 0 | 12 | 9 | 73 |
| 180 | 0 | 12 | 6 | 85 |
| 181 | 1 | 18 | 8 | 43 |
| 182 | 1 | 16 | 9 | 51 |
| 183 | 1 | 26 | 3 | 27 |
| 184 | 1 | 16 | 8 | 34 |
| 185 | 1 | 19 | 7 | 46 |
| 186 | 1 | 12 | 12 | 46 |
| 187 | 0 | 14 | 8 | 57 |
| 188 | 0 | 12 | 5 | 32 |
| 189 | 1 | 12 | 9 | 25 |
| 190 | 0 | 13 | 1 | 43 |
| 191 | 1 | 12 | 9 | 21 |
| 192 | 1 | 16 | 11 | 48 |
| 193 | 0 | 23 | 3 | 81 |
| 194 | 1 | 12 | 10 | 31 |
| 195 | 1 | 12 | 7 | 35 |
| 196 | 1 | 12 | 10 | 89 |
| 197 | 1 | 14 | 3 | 28 |
| 198 | 0 | 12 | 4 | 26 |
| 199 | 0 | 13 | 10 | 66 |
| 200 | 1 | 19 | 6 | 38 |
| 201 | 0 | 15 | 5 | 53 |
| 202 | 0 | 13 | 5 | 51 |
| 203 | 0 | 23 | 0 | 45 |
| 204 | 0 | 12 | 3 | 83 |
| 205 | 1 | 13 | 6 | 97 |
| 206 | 0 | 13 | 4 | 78 |
| 207 | 1 | 17 | 9 | 50 |
| 208 | 1 | 17 | 11 | 101 |
| 209 | 0 | 14 | 1 | 42 |
| 210 | 1 | 12 | 10 | 34 |
| 211 | 0 | 12 | 1 | 96 |
| 212 | 1 | 14 | 1 | 40 |
| 213 | 1 | 13 | 7 | 31 |
| 214 | 1 | 36 | 5 | 23 |
| 215 | 0 | 13 | 5 | 55 |
| 216 | 0 | 14 | 1 | 53 |
| 217 | 1 | 14 | 5 | 65 |
| 218 | 0 | 14 | 4 | 39 |
| 219 | 0 | 13 | 6 | 69 |
| 220 | 1 | 12 | 8 | 33 |
| 221 | 0 | 20 | 3 | 28 |
| 222 | 0 | 13 | 4 | 64 |
| 223 | 1 | 12 | 10 | 48 |
| 224 | 0 | 16 | 1 | 45 |
| 225 | 1 | 14 | 6 | 20 |
| 226 | 1 | 13 | 10 | 35 |
| 227 | 1 | 12 | 10 | 99 |
| 228 | 1 | 13 | 8 | 47 |
| 229 | 1 | 39 | 8 | 56 |
| 230 | 1 | 12 | 11 | 102 |
| 231 | 1 | 12 | 12 | 46 |
| 232 | 0 | 13 | 6 | 78 |
| 233 | 0 | 16 | 0 | 65 |
| 234 | 0 | 13 | 0 | 102 |
| 235 | 1 | 13 | 10 | 55 |
| 236 | 0 | 14 | 0 | 57 |
| 237 | 1 | 13 | 11 | 81 |
| 238 | 0 | 12 | 4 | 84 |
| 239 | 0 | 12 | 7 | 80 |
| 240 | 0 | 15 | 5 | 67 |
| 241 | 1 | 16 | 12 | 52 |
| 242 | 1 | 16 | 9 | 97 |
| 243 | 1 | 14 | 10 | 18 |
| 244 | 0 | 12 | 7 | 36 |
| 245 | 0 | 13 | 8 | 48 |
| 246 | 0 | 13 | 6 | 64 |
| 247 | 0 | 13 | 4 | 26 |
| 248 | 1 | 15 | 10 | 102 |
| 249 | 1 | 13 | 11 | 98 |
| 250 | 0 | 12 | 7 | 78 |
| 251 | 0 | 13 | 3 | 35 |
| 252 | 0 | 13 | 7 | 79 |
| 253 | 0 | 13 | 5 | 37 |
| 254 | 0 | 17 | 4 | 84 |
| 255 | 0 | 12 | 6 | 90 |
| 256 | 0 | 24 | 2 | 51 |
| 257 | 1 | 12 | 4 | 24 |
| 258 | 1 | 13 | 9 | 22 |
| 259 | 0 | 13 | 3 | 87 |
| 260 | 1 | 12 | 9 | 40 |
| 261 | 1 | 13 | 12 | 77 |
| 262 | 1 | 13 | 11 | 35 |
| 263 | 0 | 15 | 2 | 54 |
| 264 | 1 | 12 | 11 | 43 |
| 265 | 1 | 13 | 3 | 21 |
| 266 | 0 | 13 | 7 | 50 |
| 267 | 1 | 13 | 8 | 28 |
| 268 | 1 | 12 | 4 | 54 |
| 269 | 0 | 15 | 5 | 58 |
| 270 | 0 | 13 | 1 | 23 |
| 271 | 0 | 12 | 4 | 28 |
| 272 | 0 | 12 | 5 | 40 |
| 273 | 1 | 13 | 11 | 22 |
| 274 | 1 | 15 | 11 | 23 |
| 275 | 1 | 19 | 9 | 79 |
| 276 | 0 | 13 | 0 | 52 |
| 277 | 0 | 13 | 6 | 76 |
| 278 | 1 | 14 | 2 | 22 |
| 279 | 0 | 16 | 3 | 50 |
| 280 | 0 | 12 | 5 | 33 |
| 281 | 1 | 12 | 11 | 24 |
| 282 | 0 | 14 | 2 | 77 |
| 283 | 1 | 17 | 10 | 88 |
| 284 | 1 | 12 | 10 | 83 |
| 285 | 0 | 13 | 5 | 92 |
| 286 | 1 | 12 | 10 | 36 |
| 287 | 0 | 12 | 0 | 74 |
| 288 | 0 | 12 | 1 | 91 |
| 289 | 0 | 15 | 7 | 80 |
| 290 | 1 | 13 | 4 | 19 |
| 291 | 0 | 12 | 7 | 39 |
| 292 | 1 | 16 | 12 | 51 |
| 293 | 1 | 15 | 7 | 29 |
| 294 | 0 | 13 | 10 | 67 |
| 295 | 1 | 12 | 11 | 100 |
| 296 | 0 | 14 | 0 | 100 |
| 297 | 0 | 13 | 2 | 29 |
| 298 | 1 | 13 | 8 | 86 |
| 299 | 1 | 12 | 10 | 92 |
| 300 | 1 | 13 | 11 | 94 |
| 301 | 1 | 12 | 12 | 48 |
| 302 | 1 | 18 | 3 | 70 |
| 303 | 1 | 20 | 9 | 83 |
| 304 | 0 | 12 | 7 | 39 |
| 305 | 0 | 13 | 0 | 99 |
| 306 | 1 | 18 | 7 | 50 |
| 307 | 0 | 12 | 5 | 76 |
| 308 | 1 | 12 | 10 | 31 |
| 309 | 0 | 14 | 0 | 53 |
| 310 | 0 | 13 | 10 | 61 |
| 311 | 0 | 13 | 1 | 76 |
| 312 | 1 | 13 | 12 | 26 |
| 313 | 0 | 13 | 1 | 47 |
| 314 | 0 | 13 | 6 | 32 |
| 315 | 0 | 12 | 1 | 52 |
| 316 | 1 | 12 | 10 | 46 |
| 317 | 1 | 24 | 9 | 62 |
| 318 | 1 | 12 | 12 | 41 |
| 319 | 0 | 15 | 1 | 65 |
| 320 | 1 | 13 | 11 | 47 |
| 321 | 0 | 12 | 4 | 26 |
| 322 | 1 | 14 | 8 | 91 |
| 323 | 0 | 12 | 6 | 70 |
| 324 | 1 | 13 | 10 | 25 |
| 325 | 1 | 13 | 3 | 67 |
| 326 | 0 | 13 | 10 | 71 |
| 327 | 1 | 12 | 6 | 30 |
| 328 | 0 | 12 | 4 | 58 |
| 329 | 0 | 20 | 4 | 89 |
| 330 | 0 | 12 | 9 | 54 |
| 331 | 0 | 15 | 6 | 68 |
| 332 | 1 | 12 | 7 | 35 |
| 333 | 0 | 13 | 7 | 71 |
| 334 | 0 | 16 | 7 | 76 |
| 335 | 1 | 16 | 11 | 59 |
| 336 | 1 | 12 | 11 | 25 |
| 337 | 1 | 23 | 8 | 28 |
| 338 | 1 | 13 | 12 | 29 |
| 339 | 1 | 14 | 11 | 59 |
| 340 | 0 | 13 | 8 | 51 |
| 341 | 0 | 12 | 4 | 48 |
| 342 | 0 | 18 | 6 | 64 |
| 343 | 0 | 17 | 1 | 67 |
| 344 | 0 | 15 | 3 | 78 |
| 345 | 1 | 20 | 6 | 92 |
| 346 | 1 | 13 | 5 | 24 |
| 347 | 0 | 12 | 2 | 42 |
| 348 | 0 | 12 | 2 | 66 |
| 349 | 0 | 16 | 2 | 76 |
| 350 | 1 | 17 | 7 | 66 |
| 351 | 1 | 12 | 8 | 97 |
| 352 | 1 | 13 | 10 | 89 |
| 353 | 0 | 13 | 7 | 68 |
| 354 | 1 | 12 | 11 | 84 |
| 355 | 1 | 13 | 3 | 32 |
| 356 | 0 | 12 | 9 | 45 |
| 357 | 0 | 28 | 0 | 45 |
| 358 | 0 | 12 | 2 | 66 |
| 359 | 0 | 12 | 0 | 51 |
| 360 | 0 | 15 | 2 | 56 |
| 361 | 1 | 15 | 10 | 93 |
| 362 | 0 | 13 | 10 | 53 |
| 363 | 0 | 13 | 2 | 65 |
| 364 | 1 | 14 | 10 | 82 |
| 365 | 1 | 13 | 10 | 63 |
| 366 | 1 | 13 | 9 | 81 |
| 367 | 0 | 12 | 3 | 82 |
| 368 | 0 | 12 | 4 | 73 |
| 369 | 1 | 13 | 12 | 88 |
| 370 | 1 | 13 | 9 | 103 |
| 371 | 0 | 13 | 2 | 65 |
| 372 | 0 | 14 | 7 | 68 |
| 373 | 1 | 12 | 10 | 89 |
| 374 | 0 | 14 | 7 | 58 |
| 375 | 1 | 19 | 11 | 83 |
| 376 | 0 | 18 | 5 | 81 |
| 377 | 0 | 13 | 8 | 64 |
| 378 | 1 | 13 | 8 | 41 |
| 379 | 1 | 12 | 6 | 35 |
| 380 | 0 | 12 | 9 | 74 |
| 381 | 1 | 14 | 10 | 91 |
| 382 | 1 | 12 | 5 | 95 |
| 383 | 1 | 14 | 2 | 89 |
| 384 | 0 | 15 | 0 | 69 |
| 385 | 0 | 13 | 4 | 91 |
| 386 | 0 | 13 | 6 | 58 |
| 387 | 1 | 13 | 9 | 23 |
| 388 | 0 | 17 | 10 | 70 |
| 389 | 0 | 14 | 2 | 34 |
| 390 | 1 | 13 | 10 | 46 |
| 391 | 1 | 17 | 8 | 34 |
| 392 | 0 | 14 | 4 | 43 |
| 393 | 0 | 13 | 2 | 89 |
| 394 | 1 | 13 | 9 | 91 |
| 395 | 1 | 12 | 4 | 55 |
| 396 | 1 | 12 | 11 | 21 |
| 397 | 0 | 12 | 1 | 46 |
| 398 | 0 | 12 | 2 | 56 |
| 399 | 0 | 13 | 8 | 76 |
| 400 | 1 | 13 | 9 | 27 |
| 401 | 0 | 28 | 4 | 68 |
| 402 | 1 | 13 | 8 | 29 |
| 403 | 1 | 12 | 5 | 38 |
| 404 | 1 | 12 | 11 | 89 |
| 405 | 0 | 12 | 3 | 75 |
| 406 | 1 | 12 | 12 | 46 |
| 407 | 1 | 12 | 6 | 23 |
| 408 | 0 | 14 | 5 | 87 |
| 409 | 1 | 14 | 9 | 22 |
| 410 | 1 | 13 | 8 | 67 |
| 411 | 0 | 14 | 4 | 43 |
| 412 | 1 | 13 | 9 | 93 |
| 413 | 1 | 12 | 10 | 67 |
| 414 | 1 | 12 | 5 | 43 |
| 415 | 1 | 13 | 6 | 99 |
| 416 | 1 | 30 | 11 | 38 |
| 417 | 0 | 14 | 7 | 86 |
| 418 | 0 | 12 | 1 | 21 |
| 419 | 0 | 13 | 4 | 44 |
| 420 | 1 | 15 | 3 | 23 |
| 421 | 0 | 27 | 3 | 64 |
| 422 | 1 | 13 | 1 | 66 |
| 423 | 0 | 14 | 4 | 36 |
| 424 | 0 | 12 | 2 | 42 |
| 425 | 1 | 12 | 7 | 101 |
| 426 | 1 | 15 | 11 | 87 |
| 427 | 1 | 12 | 11 | 45 |
| 428 | 0 | 17 | 2 | 72 |
| 429 | 0 | 12 | 8 | 45 |
| 430 | 0 | 13 | 6 | 77 |
| 431 | 1 | 12 | 6 | 21 |
| 432 | 1 | 13 | 6 | 19 |
| 433 | 1 | 16 | 12 | 37 |
| 434 | 1 | 18 | 8 | 29 |
| 435 | 1 | 19 | 11 | 82 |
| 436 | 0 | 14 | 5 | 83 |
| 437 | 1 | 13 | 6 | 36 |
| 438 | 1 | 13 | 12 | 91 |
| 439 | 0 | 15 | 6 | 59 |
| 440 | 0 | 15 | 8 | 46 |
| 441 | 0 | 13 | 3 | 87 |
| 442 | 0 | 19 | 6 | 82 |
| 443 | 1 | 13 | 3 | 22 |
| 444 | 1 | 13 | 12 | 68 |
| 445 | 1 | 12 | 11 | 51 |
| 446 | 1 | 12 | 3 | 102 |
| 447 | 1 | 12 | 10 | 71 |
| 448 | 0 | 13 | 9 | 80 |
| 449 | 0 | 20 | 5 | 70 |
| 450 | 1 | 12 | 5 | 24 |
| 451 | 0 | 12 | 4 | 90 |
| 452 | 1 | 13 | 7 | 49 |
| 453 | 0 | 13 | 1 | 37 |
| 454 | 1 | 14 | 11 | 68 |
| 455 | 1 | 13 | 12 | 40 |
| 456 | 0 | 16 | 8 | 60 |
| 457 | 0 | 20 | 6 | 48 |
| 458 | 0 | 13 | 8 | 39 |
| 459 | 0 | 14 | 7 | 73 |
| 460 | 0 | 12 | 5 | 31 |
| 461 | 0 | 13 | 5 | 86 |
| 462 | 0 | 12 | 1 | 63 |
| 463 | 0 | 15 | 3 | 37 |
| 464 | 0 | 14 | 6 | 37 |
| 465 | 0 | 15 | 3 | 86 |
| 466 | 1 | 13 | 12 | 22 |
| 467 | 0 | 12 | 4 | 37 |
| 468 | 0 | 12 | 0 | 70 |
| 469 | 0 | 14 | 8 | 47 |
| 470 | 0 | 12 | 5 | 60 |
| 471 | 1 | 13 | 6 | 28 |
| 472 | 0 | 23 | 2 | 66 |
| 473 | 1 | 14 | 5 | 18 |
| 474 | 1 | 12 | 11 | 65 |
| 475 | 1 | 16 | 11 | 51 |
| 476 | 0 | 12 | 1 | 36 |
| 477 | 1 | 12 | 8 | 89 |
| 478 | 0 | 12 | 8 | 51 |
| 479 | 1 | 13 | 10 | 86 |
| 480 | 0 | 12 | 2 | 44 |
| 481 | 1 | 14 | 11 | 82 |
| 482 | 0 | 14 | 7 | 69 |
| 483 | 0 | 12 | 5 | 58 |
| 484 | 1 | 14 | 11 | 86 |
| 485 | 1 | 12 | 9 | 70 |
| 486 | 0 | 15 | 4 | 57 |
| 487 | 0 | 12 | 4 | 41 |
| 488 | 0 | 14 | 5 | 91 |
| 489 | 0 | 12 | 3 | 89 |
| 490 | 1 | 16 | 8 | 31 |
| 491 | 1 | 12 | 6 | 42 |
| 492 | 0 | 12 | 7 | 48 |
| 493 | 0 | 13 | 1 | 24 |
| 494 | 1 | 18 | 6 | 38 |
| 495 | 0 | 15 | 1 | 41 |
| 496 | 0 | 15 | 2 | 97 |
| 497 | 0 | 20 | 5 | 72 |
| 498 | 1 | 41 | 11 | 52 |
| 499 | 1 | 16 | 11 | 74 |
| 500 | 1 | 13 | 2 | 32 |
Splitting the data into training and testing sets
sample_index <-
train <-
test <- Fit the logistic regression model
Develop the logistic regression model for the Spam dataset.
If you cannot write your own codes, try to ask EducateUsGPT assistant to help you out.
Ask Educate Us GPT
What question you should ask?
Making predictions
train_pred <- predict(Logit_mod, newdata=train, type='response')
test_pred <- predict(Logit_mod, newdata=test, type='response')Evaluating the model
Ask Educate Us GPT
What are the popular evaluation metrics of a logistic regression model?
Accuracy ratio
It measures the proportion of correctly classified instances out of the total instances.
\[\text{Accuracy} = \frac{\text{Number of Correct Predictions}}{\text{Total Number of Predictions}} \times 100\% \] Based on the confusion matrix we introduced before, the accuracy ratio can be written as: \[\text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} \times 100\%\]
# Evaluating the accuracy
train_accuracy <- mean((train_pred > 0.5) == train$Spam)
print(paste('Train_Accuracy:', train_accuracy))[1] "Train_Accuracy: 0.78"test_accuracy <- mean((test_pred > 0.5) == test$Spam)
print(paste('Test_Accuracy:', test_accuracy))[1] "Test_Accuracy: 0.86"ROC Curve and area under the ROC curve (AUC-ROC)
We will thoroughly introduce the ROC and AUC-ROC in a separate tutorial.
# Calculating AUC for training and testing sets
library(pROC)
train_auc <- roc(train$Spam, train_pred)
test_auc <- roc(test$Spam, test_pred)
train_auc; test_auc
Call:
roc.default(response = train$Spam, predictor = train_pred)
Data: train_pred in 188 controls (train$Spam 0) < 212 cases (train$Spam 1).
Area under the curve: 0.8606
Call:
roc.default(response = test$Spam, predictor = test_pred)
Data: test_pred in 54 controls (test$Spam 0) < 46 cases (test$Spam 1).
Area under the curve: 0.8917